
Хочу представить пример шаблонного парсера интернет-магазина. Пример ни как не претендует на звание универсального инструмента для получения структурированных данных из интернет магазина, но возможно подойдет для некоторых шаблонных интернет магазинов коих в интернете очень много.

Итак, в качестве инструмента для парсинга сайта я использую SlimerJS.
Пример постарался привести как можно в более упрощенном и универсальном виде.
Итак, точка входа:
script.js
var grab = require('./grab'); // подключение модуля
grab.create().init('/catalog'); // инициализация парсераЗдесь происходит подключение модуля парсера и его инициализация, а в метод init() передается URL страницы
каталога товаров, ссылка является относительной. Основной домен сайта задается в файле config.js
Вся логика парсера находиться в файле grab.js. Я его разделил на две части, первая часть представляет собой объект обертку над SlimerJS для одновременной работы нескольких копий браузера. Все комментарии по коду я вынес в листинг в целях упрощения понимания кода.
grab.js
var file = require("./file").create(); // подключение модуля для работы с файловой системой
var config = require("./config").getConfig(); // подключение глобальных переменных
/**
* создаем объект-конструктор
*/
function Grab() {
this.page; // храним текущий объект "webpage"
this.current_url; // сохраняем текущий URL
this.parentCategory; // сохраняем категорию продукта
/**
* метод инициализует объект
* @param url string относительный адрес ( /contacts )
* @param parent
*/
this.init = function(url, parent) {
this.page = require("webpage").create(); // создаем объект webpage
this.callbackInit(); // определяем callback для объекта webpage
if(url) { // если параметра нет, то обращаемся к домену
config.host += url;
}
this.parentCategory = parent;
this.open(config.host); // открыть URL
};
/**
* открыть URL
* @param {string} url адрес который нужно открыть
*/
this.open = function(url) {
/*
* место для возможной бизнес логики
*/
this.page.open(url);
};
/**
* завершить работы с текущим окном
*/
this.close = function() {
this.page.close()
};
/**
* инициализация callback
*/
this.callbackInit = function() {
var self = this;
/**
* метод вызывается при возникновение ошибки
* @param {string} message error
* @param {type} stack
*/
this.page.onError = function (message, stack) {
console.log(message);
};
/**
* метод вызывается при редиректе или открытий новой страницы
* @param {string} url новый URL
*/
this.page.onUrlChanged = function (url) {
self.current_url = url; // сохраняем URL как текущий
};
/**
* метод вызывается если в объекте webpage срабатывает метод console.log()
* @param {string} message
* @param {type} line
* @param {type} file
*/
this.page.onConsoleMessage = function (message, line, file) {
console.log(message); // выводим его в текущую область видимости
};
/**
* метод вызывается при каждой загрузке страницы
* @param {string} status статус загрузки страницы
*/
this.page.onLoadFinished = function(status) {
if(status !== 'success') {
console.log("Sorry, the page is not loaded");
self.close();
}
self.route(); // вызываем основной метод бизнес логики
};
};
}Вторая часть файла, определяет поведение и расширяет созданный объект Grab
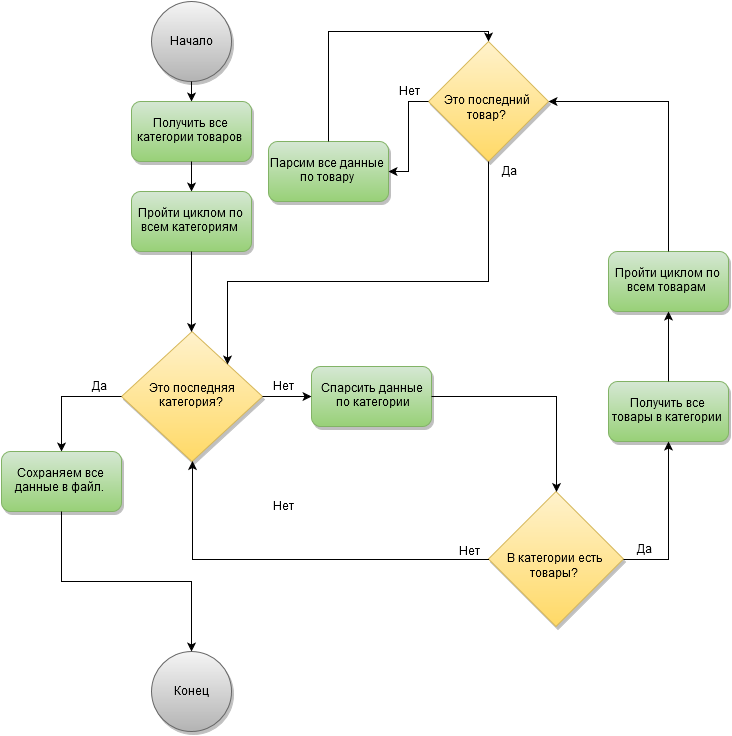
Grab.prototype.route = function() {
try {
// если текущая страница это страница содержащая категории продуктов
if(this.isCategoryPage()) {
var categories = this.getCategories(); // спарсить данные со страницы категории
file.writeJson(config.result_file, categories, 'a'); // записать данные в файл
for (var i = 0; i < categories.length; i++) { // пройти все категории товаров
var url = categories[i].url_article; // получаем URL на страницу с товарами текущей категории
new Grab().init(url, categories[i].title); // открываем новую страницу
slimer.wait(3000); // ждем 3 секунды, до открытия следующей страницы
}
} else {
// текущая страница является карточкой товара
var content = this.getContent(); // спарсить данные с карточки товара
file.writeJson(config.result_file, content, 'a'); // записать результат в файл
this.close(); // закрыть текущее окно
}
this.close();
} catch(err) {
console.log(err);
this.close();
}
};
/**
* получить со страницы весь контент относящийся к категориям
* @returns {Object}
*/
Grab.prototype.getCategories = function() {
return this.getContent('categories')
};
/**
* проверить содержит ли текущая страница категории товаров
* @returns {bool}
*/
Grab.prototype.isCategoryPage = function() {
return this.page.evaluate(function() {
// определить присутствуют ли данные относящиеся к странице товаров
return !$(".catalog-list .item .price").length;
});
};
/**
* получить полезные данные со страницы
* @param {string} typeContent какие данные нужно получить {categories|product}
* @returns {Object}
*/
Grab.prototype.getContent = function(typeContent) {
var result = this.page.evaluate(function(typeContent) {
var result = [];
// находим блок в котором находяться структурированные данные (страница категорий и продуктов имеют одинаковую разметку)
$(".catalog-list .item").each(function(key, value) {
var $link = $(value).find('a.name'); // кешируем ссылку
var obj = { // собираем даные относящиеся к категории
'type': 'category',
'title': $link.text().trim().toLowerCase(), // заголовок категории
'url_article': $link.attr('href'), // ссылка на товары входящие в эту категорию
'url_article_image': $(value).find('a.img > img').attr('src')
};
// если это карточка товара, то собираем данные относящиеся к карточке товара
if(typeContent !== 'categories') {
obj.size = [];
obj.type = 'product';
$('.razmers:first .pink').each(function(key, value) { // размеры|цвет|дагональ...
obj.size.push($(value).text().trim());
});
obj.price = parseInt($(value).find('.price').text(), 10); // цена
}
result.push(obj);
});
return result;
}, typeContent);
return result;
};
exports.create = function() {
return new Grab();
};Для удобной работы с файловой системой в SlimerJS предусмотрен API который позволяет как читать так и записывать данные
file.js
var fs = require('fs');
/**
* инициализация объекта обертки
*/
function FileHelper() {
/**
* чтение данных
* @param {string} path_to_file относительный путь до файла
* @returns array - данные
*/
this.read = function(path_to_file) {
if(!fs.isFile(path_to_file)){
throw new Error('File ('+path_to_file+') not found');
}
var content = fs.read(path_to_file);
if(!content.length) {
throw new Error('File ('+path_to_file+') empty');
}
return content.split("\n");
};
/**
* записать данные в файл
* @param {string} path_to_file относительный путь до файла
* @param {string} content данные для записи
* @param {string} mode режимы работы 'r', 'w', 'a/+', 'b'
*/
this.write = function(path_to_file, content, mode) {
fs.write(path_to_file, content, mode);
}
/**
* запись данных в виде JSON
* @param {string} path_to_file относительный путь до файла
* @param {array} content данные для записи
* @param {string} mode режимы работы 'r', 'w', 'a/+', 'b'
*/
this.writeJson = function(path_to_file, content, mode) {
var result = '';
for(var i=0; i < content.length; i++) {
result += JSON.stringify(content[i]) + "\n";
}
this.write(path_to_file, result, mode);
}
}
exports.create = function() {
return new FileHelper();
};И последний файл, это файл конфигурации в котором можно указать переменные общие для всей системы
config.js
var Config = function() {
this.host = 'http://example.ru';
this.log_path = 'logs\\error.txt';
this.result_file = 'result\\result.txt';
};
exports.getConfig = function() {
return new Config();
};Результат работы будет в виде файла, который можно будет обработать для дальнейшего экспорта данных
Запускаеться скрипт командой из консоли
slimerjs script.js